← Back to home
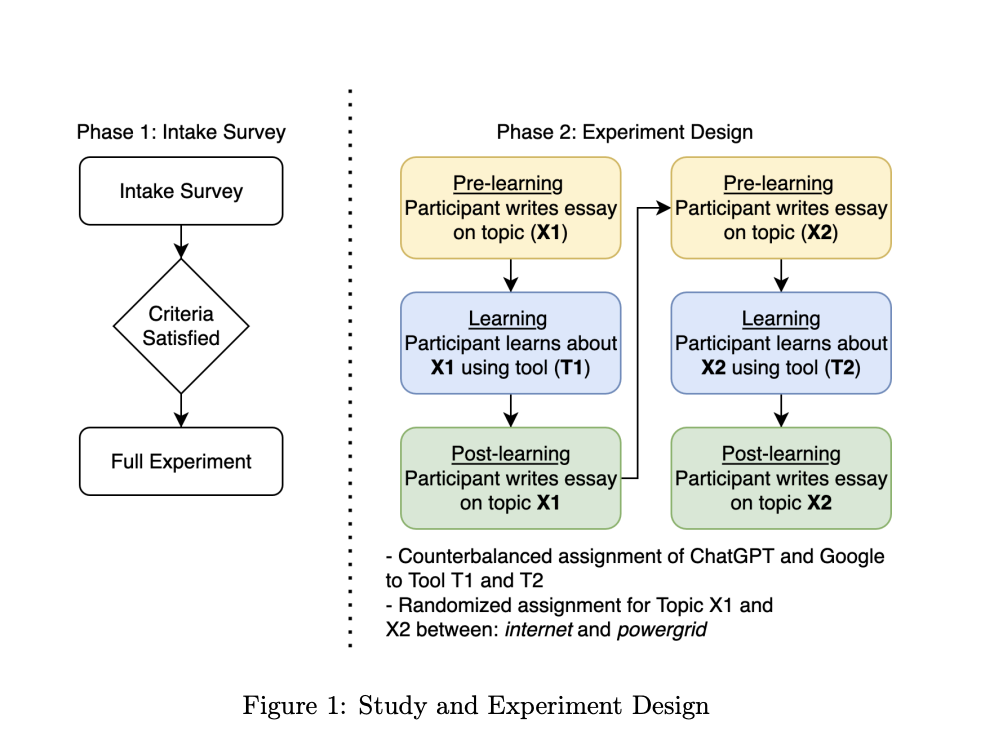
Controlled within-subjects design: 20 students learned two technical topics using either ChatGPT or Google; we compared inputs, outputs, and expert-graded outcomes.
Exploring the Interaction–Outcome Paradox in Learning with LLMs
Co-authored research on how university students learn with AI vs. search – accepted to AIED 2025 (Italy) & presented at UXPA Boston 2025.
Context
- Undergraduate Research Assistant, Bentley Experience Design Department
- Study compared how students learn with ChatGPT vs. traditional search
- Measured interaction quality + learning outcomes + fairness (e.g. plagiarism flags)
What I did
- Designed and piloted study materials; recruited and ran 20 participants
- Coded screen recordings and transcripts (prompt types, lexical richness, behavior)
- Graded essays across seven dimensions; compared to pre-learning baselines
- Co-synthesized findings and contributed to paper and conference presentations
Results
- Interaction–Outcome Paradox: LLMs → richer, more self-aware prompts, but learning outcomes didn’t significantly beat search
- Essays after search were more often flagged for plagiarism by common tools than LLM-based ones
- Co-authored paper accepted to AIED 2025 (Italy); presented at UXPA Boston 2025
Key Findings
Finding 01
Richer ≠ better grades
LLM interactions looked deeper and more self‑aware, but students’ essay scores stayed similar to those after search.
Finding 02
Effort shifts
Students spent less time stitching sources and more time prompting and refining explanations — a different kind of work, not less.
Finding 03
Plagiarism paradox
Essays after search were more often flagged for plagiarism than LLM‑based ones, even when students were trying to do the right thing.
Finding 04
Design challenge
The tension between interaction and outcome is a UX problem: tools and assessments need to reward real learning, not just AI‑polished writing.
Curious about the study design, full findings, and the paradox?